IETFに「New UUID Formats」という提案仕様が提出されています。
これは、時系列順にソート可能なUUID version 6, UUID version 7, UUID version 8を新しく定義するものです。
詳しい背景は提案仕様にゆずりますが、ULIDを始めとして、時系列順にソート可能な一意な識別子を利用したいというユースケースがあります。例えば、データベースのキーとして使えば、ソートせずとも順番に並びますし、書き込む際も順々に書き込めるのでデータアクセスが局所的になります。
今回は簡単に、それぞれのUUIDのフォーマットを眺めていきます。なお、フォーマットは異なりますが、バージョンを示す値は同じ位置にあります。
UUIDv6
UUIDv6は128bit長で、UUIDv1と似てるフォーマットを取ります。

1582年10月15日(グレゴリオ暦)からの100ナノ秒単位でカウントした数値を60bit長で表現し、time_high(32bit), time_mid(16bit), time_low(12bit)に分割して並べます。
なお、time_low_and_versionは上位4bitがバージョンであり、6をしめす 0110 が入ります。
残りの部分はUUIDv1と同じで、クロックシーケンスおよび乱数が入ります。
UUIDv7
UUIDv7はユニックスタイムを使用し、ミリ秒、マイクロ秒、ナノ秒精度のタイムスタンプを表現できます。
UUIDv7の構成は、36bitのタイムスタンプ(unixts)、小数点以下の値(msecor usec or nsec)、乱数(rand)から構成されます。
ミリ秒精度の場合

マイクロ秒精度の場合
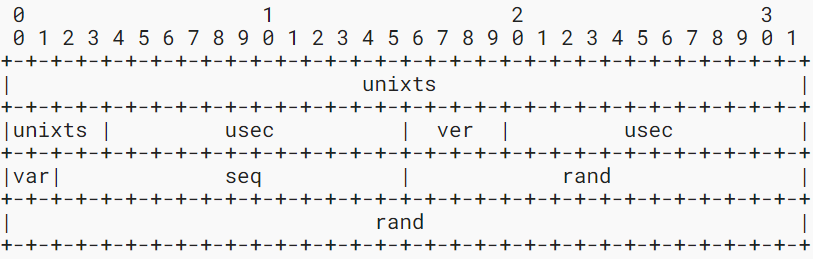
ナノ秒精度の場合

システムによって扱える精度が異なりますが、ナノ秒でエンコードされたものを、マイクロ秒としてデコードしても残りはランダムな値として処理することが出来ます。
UUIDv8
UUIDv8は他のバージョンが使えない場合のみに使います。時間ソースとして何を使うかや、その精度を自由にきめて使用出来ます。どのようにエンコードされているか知らない実装は、タイムスタンプを得ることは出来ません。
フォーマットはタイムスタンプ、バージョン、シーケンスやノード(乱数)の位置のみが決められています。
