IETFのHTTP WGで『Retrofit Structured Fields for HTTP』という提案仕様が出ているので簡単に紹介する
Structured Field Values for HTTP
前提にある「Structured Field Values for HTTP」についてまず触れる。
HTTPでは、HTTPヘッダ(フィールド)の値を構造化データとして扱えるようにする「RFC 8941 Structured Field Values for HTTP」という仕様があります。
その仕様では、ListやDictionaryといったタイプが定義されています。
例:
Example-List: sugar, tea, rum
Example-Dict: a=?0, b, c; foo=bar
Structured Field Valuesの目的は主に2つあります
- 新しいHTTPヘッダを定義する際につどABNFで定義を与えるのではなく、Structured Field ValuesのTypeで構文定義を与えられるようにする
- パーサーを再利用可能にする
既存のHTTPヘッダに適応することは RFC 8941ではスコープには入っておりませんでした。既存のHTTPヘッダもStructured Field Valuesとしてパースしようというのが『Retrofit Structured Fields for HTTP』になります。
Retrofit Structured Fields for HTTP
『Retrofit Structured Fields for HTTP』では、すでに使用されているHTTPヘッダをStructured Field Valuesとしてパースすることを目的とした仕様です。
戦略は2つあります
- そのままStructured Field Valuesとしてパースしても問題なさそうなヘッダを指定する
- それ以外のものは、新しくStructured Field Valuesとしてマップする
具体例を見ると分かりやすいかと思います
Structured Field Valuesとしてパースする
すでに使われているHTTPヘッダでパースできそうなものは、提案仕様のなかでこのように羅列されます。
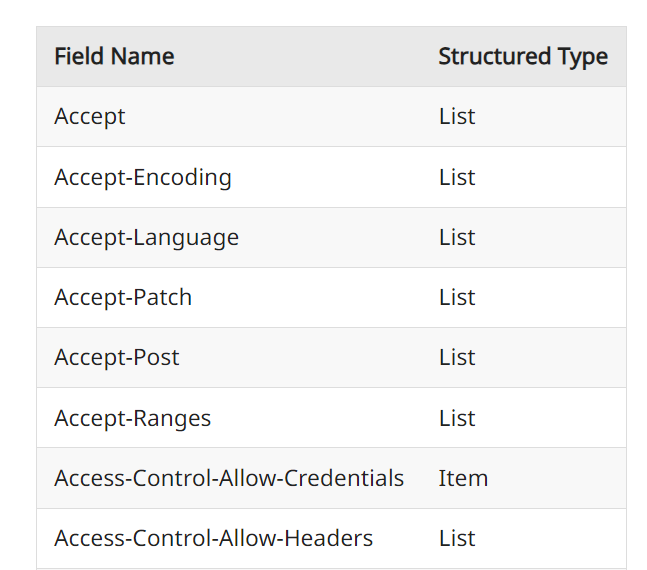
ただし注意点があり、Structured Field Valuesとして扱う上で次のことを気をつけなければなりません
- Dictionaryのパラメータキーとして大文字・小文字を区別するケース。クオートのルール
- 構文エラー時の挙動の違い
- integerは15桁まで
- 値が空文字の場合エラーとなる
- Alt-Svc, Content-Length, Retry-After などは実装や一部互換性の無い値が知られている
Structured Field Valuesとしてマップする
すでに使われているHTTPヘッダでパースできないものは、マップした値をいれられるものとします。
例えば、Dateヘッダは
Date: Sun, 06 Nov 1994 08:49:37 GMT
DateタイプをもつSF-Dateを定義します。
SF-Date: @784111777
このように次のヘッダはマップしたものが定義されます
- SF-Content-Location (Item)
- SF-Cookie (List)
- SF-Date (Item)
- SF-ETag (Item)
- SF-Expires (Item)
- SF-If-Match (List)
- SF-If-Modified-Since (Item)
- SF-If-None-Match (List)
- SF-If-Unmodified-Since (Item)
- SF-Last-Modified (Item)
- SF-Location (Item)
- SF-Referer (Item)
- SF-Set-Cookie (List)









